
Jupinder Parmar
Research Scientist, NVIDIA
jasparmar [AT] alumni [DOT] stanford [DOT] edu
Observational Supervision
Using Passively Observed Human Signals To Improve Medical Imaging Architectures
 Overview:
Medical imaging is an especially important application area for supervised machine learning methods. However, many recently proposed deep learning architectures that have achieved impressive results in the greater computer vision domain rely on massive amounts of hand-labeled data. Obtaining said datasets in the medical setting is an extremely difficult task as it requires large amounts of physician time which has mitigated advancements and has hampered the ability to improve clinical outcomes.
Overview:
Medical imaging is an especially important application area for supervised machine learning methods. However, many recently proposed deep learning architectures that have achieved impressive results in the greater computer vision domain rely on massive amounts of hand-labeled data. Obtaining said datasets in the medical setting is an extremely difficult task as it requires large amounts of physician time which has mitigated advancements and has hampered the ability to improve clinical outcomes.
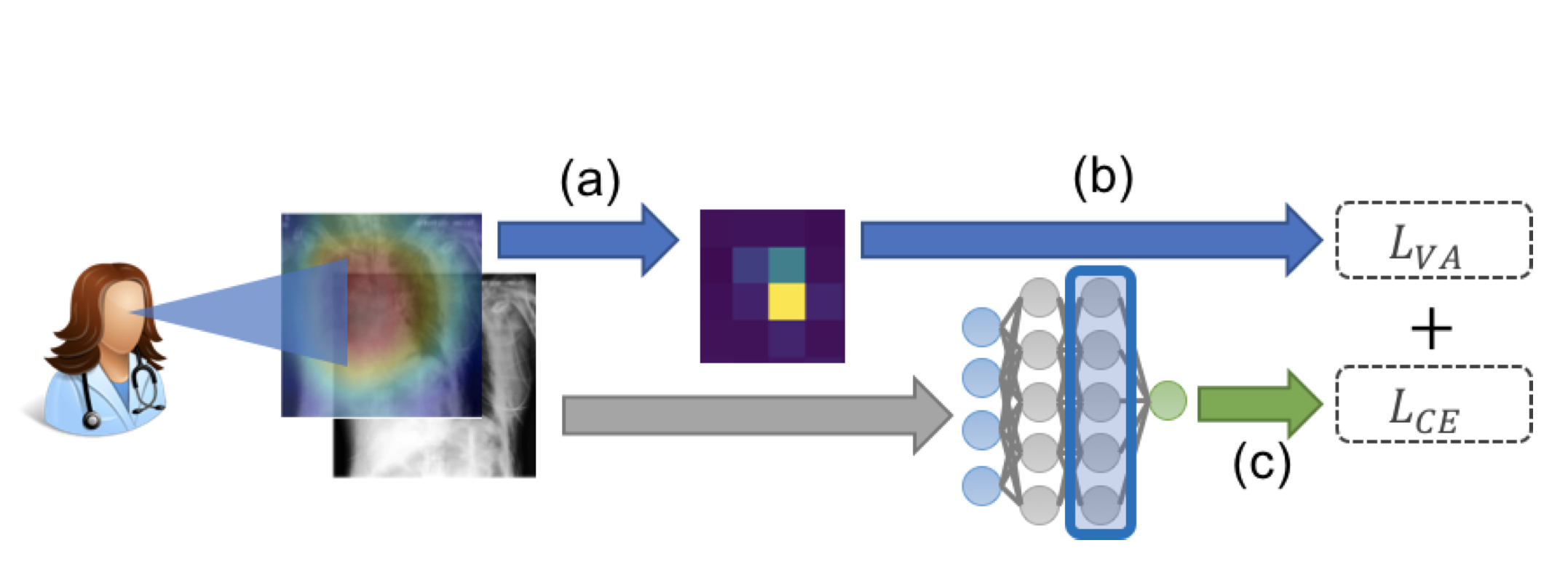
Hence, there is a need to create architectures that are able to provide gains while using less data. In order to acccomplish such a task, we have been exploring rich observational signals that can be passively collected at annotation time such as eye tracking data which describes the path a person’s gaze took while performing a task. This gaze data can be collected while a physician is labeling a dataset causing no additional time cost and has been made possible by recent advacenements in eye traching techonology. We believe that the signals provided to us by this passively observed signal can help us train models to draw influence from the same spatial regions most heavily utilized by the human annotator and hence lead to performance improvements.
To best utilize this gaze data we currently have been researching incorporating it within an attention layer in our architecture. At a high level, we first extract a rich feature map of an image from a ResNet which we then pass into our attention layer. This attention layer iterates over the locations focused on in the gaze sequence to train a soft attention mechanism and output an attention feature map of the image that highlights the most impactful spatial regions of the image as determined by the gaze data. This attention feature map is then used to regularize the feature map output by the ResNet model to allow our model to pay attention to those regions when it is producing it’s classification score.